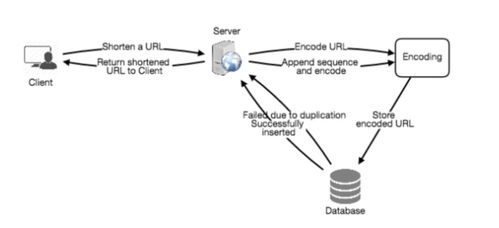
在現代分布式系統中,后端服務的性能直接決定了用戶體驗和業務承載能力。特別是在數據處理與存儲支持服務這類核心基礎設施上,性能瓶頸往往成為系統擴展的掣肘。因此,系統性的性能壓測不僅是上線前的必要環節,更是持續優化與架構演進的重要依據。本文將探討針對此類服務的壓測實踐,涵蓋目標設定、場景設計、工具選型、瓶頸分析與優化策略。
一、明確壓測目標與關鍵指標
性能壓測的首要步驟是定義清晰的目標。對于數據處理與存儲服務,核心指標通常包括:
- 吞吐量:單位時間內成功處理的請求數(QPS/TPS),特別是在數據寫入、查詢、聚合等場景下的峰值能力。
- 響應時間:P50、P95、P99等百分位延遲,直接關聯用戶體驗。對于存儲服務,P99延遲的穩定性尤為關鍵。
- 資源利用率:CPU、內存、磁盤I/O、網絡帶寬的使用率,目標是找出資源瓶頸(如CPU密集型計算或I/O等待)。
- 錯誤率:在高壓下服務返回錯誤(如超時、連接失敗、數據不一致)的比例。
- 系統穩定性與恢復能力:在持續負載下服務是否出現性能劣化,以及負載驟降后能否快速恢復。
二、構建貼近生產的壓測場景
壓測場景的設計必須模擬真實業務流量。對于數據處理與存儲服務,需重點關注:
- 數據模型與容量:使用與生產環境相似的數據結構、索引和初始數據量。壓測數據庫時,預填充一定規模的數據(如TB級別)以模擬線上狀態。
- 請求混合比例:根據業務特征,合理配置讀寫操作的比例(例如,寫入:查詢 = 3:7),并包含復雜查詢、批量操作、事務處理等關鍵路徑。
- 流量模型:采用階梯增壓、波浪型或穩態持續壓力等模式,分別驗證服務的彈性伸縮極限和長穩運行能力。
- 依賴服務模擬:使用像WireMock、MockServer等工具模擬上下游服務,避免壓測期間對真實外部系統造成影響。
三、工具鏈選擇與實施
選擇合適的工具能事半功倍。常見的壓測工具包括:
- 負載生成:JMeter、Gatling、k6等適用于API層壓測;對于存儲層,亦可使用專用工具如sysbench(數據庫)、YCSB(NoSQL)。
- 監控與可觀測性:這是壓測的“眼睛”。需整合基礎設施監控(如Prometheus+Grafana采集服務器指標)、應用性能監控(APM,如SkyWalking, Pinpoint)以及數據庫慢查詢日志、連接池狀態等。
- 分布式壓測:當單機無法產生足夠壓力時,需采用分布式壓測集群,并確保時鐘同步和結果匯聚。
實施時,應遵循從單接口到混合場景、從單服務到全鏈路、從測試環境到生產影子壓測的漸進過程。
四、典型瓶頸分析與優化策略
壓測的核心價值在于暴露問題。針對數據處理與存儲服務,常見瓶頸及應對思路包括:
- 數據庫連接池耗盡:表現是大量請求超時。優化方法包括調整連接池大小(如HikariCP配置)、引入讀寫分離、優化事務范圍、或使用連接更輕量的驅動。
- 慢查詢與索引失效:高并發下,一個未走索引的查詢可能拖垮整個實例。通過分析慢日志,針對性添加或優化復合索引,避免全表掃描。對于復雜聚合,考慮預計算或使用物化視圖。
- 磁盤I/O瓶頸:表現為IO等待過高,TPS上不去。可考慮使用SSD、增加磁盤陣列、優化日志寫入策略(如組提交),或對熱數據進行緩存(如Redis)。
- 序列化/反序列化成本高:特別是在處理大量數據對象時。可評估更高效的序列化協議(如Protobuf、Msgpack),或優化Java對象轉換流程。
- 鎖競爭激烈:在高并發更新場景下,行鎖、表鎖甚至分布式鎖都可能成為瓶頸。優化策略包括減少事務粒度、使用樂觀鎖、或通過隊列異步化寫操作。
- 內存與GC壓力:長時間壓測可能引發內存泄漏或頻繁Full GC。需分析堆內存使用,優化數據結構和緩存策略,調整JVM參數。
五、建立性能基線與持續回歸
每次重大迭代后,都應進行性能回歸測試,與歷史基線(Baseline)對比,防止代碼變更引入性能衰退。將性能測試納入CI/CD流水線,作為準出標準之一。
對數據處理與存儲支持服務的性能壓測,是一項貫穿于設計、開發與運維全周期的系統工程。它不僅是發現瓶頸的技術手段,更是推動架構合理化、資源精細化管理的驅動力。通過科學的壓測實踐,團隊能夠構建出既滿足當前業務峰值,又具備彈性伸縮潛力的穩健后端服務,為業務的快速發展奠定堅實的技術基石。